
https://proceedings.mlr.press/v80/jiang18c.html
次のSurveyでも紹介された。
📄![]() 2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
CNNやDNNは高い学習能力を持つが、特にNoisy LabelではNoisyな部分の特徴まで覚えて「しまう」過学習の問題を抱える。
近年、Noisy Labelの学習の損失の中に、カリキュラムという項を加える手法が広まっている。これは、機械学習をするときに人間が意図させる順番で知識を学習してもらうことを促す手法。ただ、現行のカリキュラム学習では、カリキュラムが事前に定まっていて、Student Modelからのフィードバックを元に改善することはない。
この論文ではMentor Netというすでにあるカリキュラムをもとに、Studentに教えるカリキュラムを作る or データ駆動で自動でカリキュラムを作る手法を開発した。そして、Student Netのフィードバックを元にMentor Netも更新されていく。テスト時にはStudent NetはMentor Netの判断を仰がずに推論していく。
カリキュラム学習の定義
目当ての訓練モデルはStudent Modelといい、 とする。wはそのモデルの重み。Student Modelの損失は、と書くことができる。カリキュラム学習は以下の損失項において、各サンプルの損失の重みをコントロールする について何かしらの制約を課したを追加する。
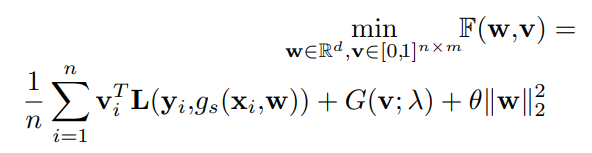
ここでは0か1で構成されており、n行m列である(カテゴリ)という。
既存の手法では、は片方を固定してもう片方を最適化を行うことを交互にやるという手法であった。そのうえで、Kumarの先行研究では以下のようにカリキュラムを定義。
この場合、を固定した時にの最適化は、先行研究で各がすべて0か全て1であるという制約の下では、以下のように更新していくことで、カリキュラムを実現する。
これがsmall-loss trickを実現させている。の更新では必ず最適化ではなく(←これほんと?実は最適化では?)、進んでほしい方向に誘導していることに注意。
このカリキュラムについて、人工的にいろいろ設定したのが諸先行研究である。
データからカリキュラムの自動学習
この論文では、Mentor Netを学習します。このネットワークではパラメタのを学習することで、から予測するのはである(ただこの論文もベクトルと書いているが成分はすべて同じ値を取るような感じ)
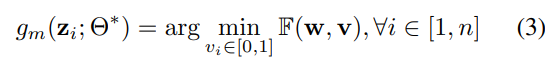
既存のカリキュラムからの学習
事前に存在するカリキュラムがあるとして、それを元にMentor Netは正しいを出力させるのが第一目標。これ自体は既存の研究と同じことをやっているともいえる。
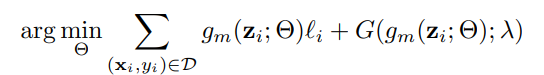
やりたいこととしては上の式。
ここで、カリキュラムの形が以下の形であるとする。この形ならばよく網羅できる、という感じ。
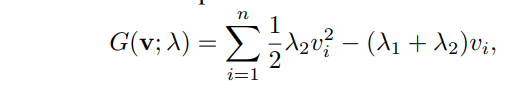
このかたちのもとで、を固定してを動かすときの関数は以下のように見なせる。はハイパーパラメタ。
これを動かして,、small-loss trickの前提で最適化をする時以下の解を得る。
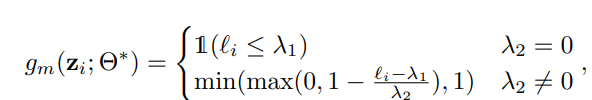
二項目は0と1の間に値を制限していると言える。既存のに加えて、多少閾値を超えてもMentor Netは重みを0以外で返すした。超えているのが多いほど、の出力たる重みは下がっていく。なお、そもそもとなると0としているらしい。
データ駆動でMentor Netを学習する場合
他かサブデータセットかはわからないが、本来のデータセットよりずっと小さいを使ってMentor Netを訓練する。そして、Mentor Netからくるを使ってStudent Net(本来の識別器)を訓練する形。そして、1. 今のStudent Netを使いMentor Netを訓練。 2. Mentor Netを使いStudent Netを訓練。のような形である。アルゴリズムは具体的には次の図。

最初の始動するときのMentor Netでは、で手動で訓練に使うべきかどうかに相当する、(ラベルは正しい) or 0(間違っている)を与える。
実際の訓練では、最初の20%のエポックだけ、の予測をの確率のベルヌーイ分布にする、つまりランダムでの確率で学習に使わない=学習データのドロップアウトを行う。これは、burn-inというプロセスで、学習の安定性を上げることができる。
なお、とのドメインがたとえ違うとも、Mentor Netの訓練は有効である。(MNIST-10での事前訓練はMNIST-100でも有効だったり)
Mentor Netの構造
DNNの表現力は任意の関数を作れるので、Mentor Netを構築できるが現実的には以下のようなアーキテクチャを提案した。
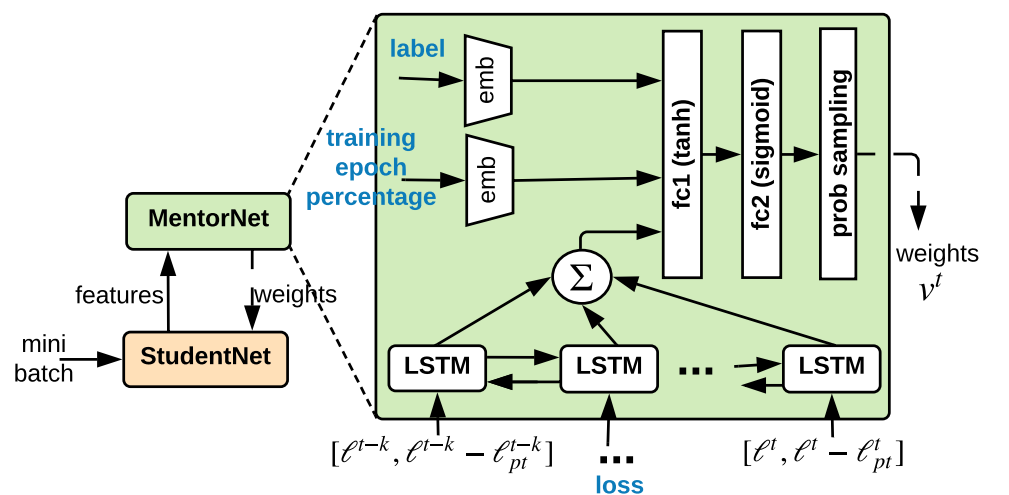
の入力として、サンプル、予測ラベル、与えられたラベル、損失、訓練の進度を表す0から99の実数(全体の何割のepochが進んだか)がある。それに加えて、LSTMで持っている損失の指数移動平均も使うことになる。
まず、与えられたラベルと訓練進度を埋め込む。そこにLSTMからの記憶情報も混ぜて、3層のDNNに入れて重みを出力させる。
LSTMには、合計個存在し、それぞれ前までの損失、そして指数移動損失を入れる。先行研究によれば、これで予測分散(Prediction Variance)を捉えやすくなるらしい。